




Just In: This new 🔥 LLM outperforms on all important benchmarks like MMLU, HellaSwag, TruthfulQA, and ARC.
You often hear these 4 most important benchmarks 📊 names every time a new LLM is out. But what do they actually mean 😦?
✅ Clearly explained (with example): 👇
MMLU 📚
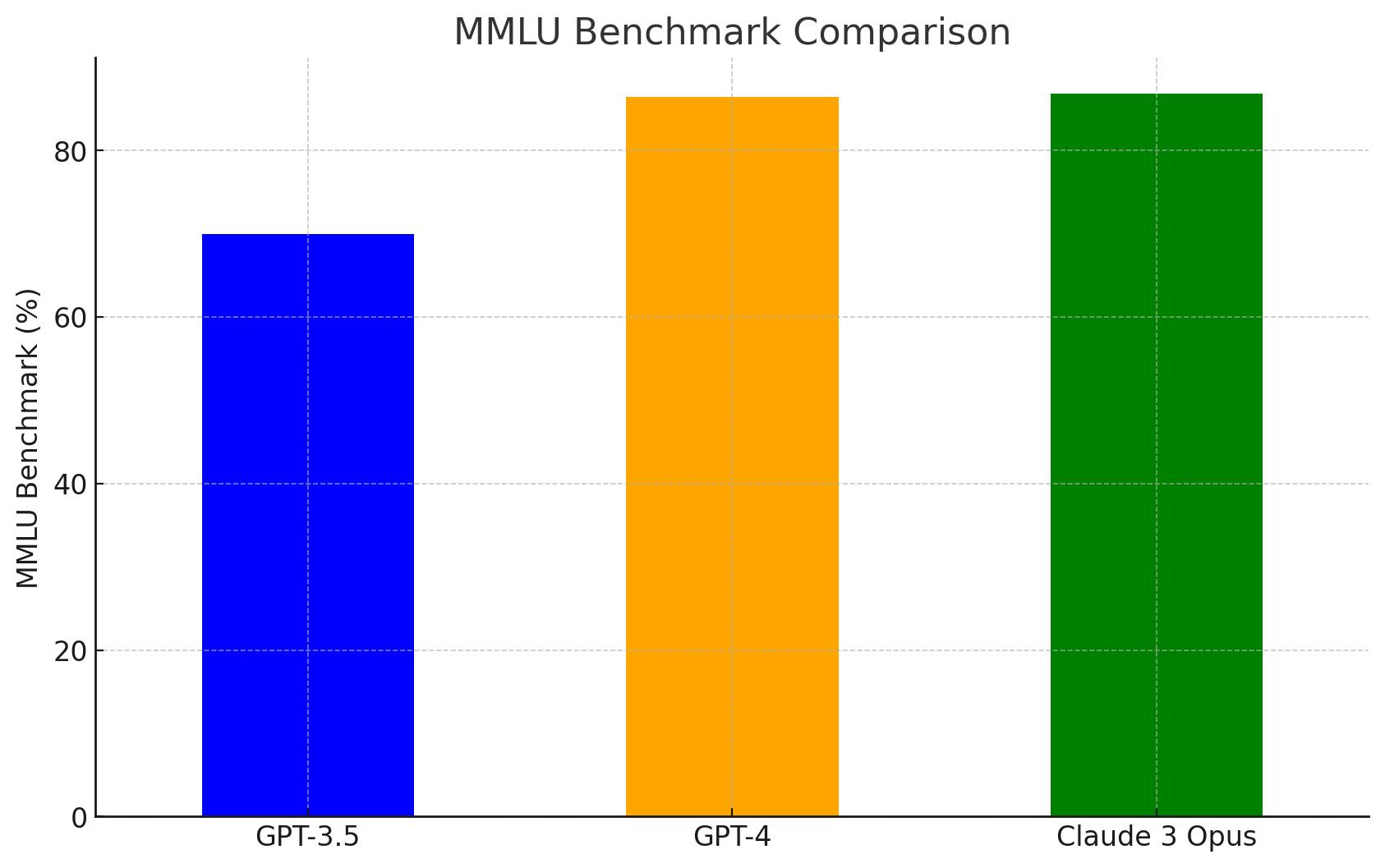
Massive Multitask Language Understanding (MMLU) tests model ability across a wide range of subjects and knowledge domains. It consists of 57 tasks, from areas such as elementary mathematics ➕, US history 🇺🇸, computer science 💻, law ⚖️, and more.
Example Question Of Literature Domain:
Question:
"In Shakespeare's play 'Romeo and Juliet,' what causes the tragic ending of the two main characters?"
Choices:
A) A misunderstanding
B) A war between two countries
C) The discovery of a secret treasure
D) A magical curse
Correct Answer: A) A misunderstanding.
In summary, the MMLU measures a model's ability to answer questions in areas it hasn't been explicitly trained on 🎓, assessing its generalization skills 🧠 and ability to have knowledge of different domains 🌐.
The next one is quite interesting 👯♀️.
HellaSwag 🌍:
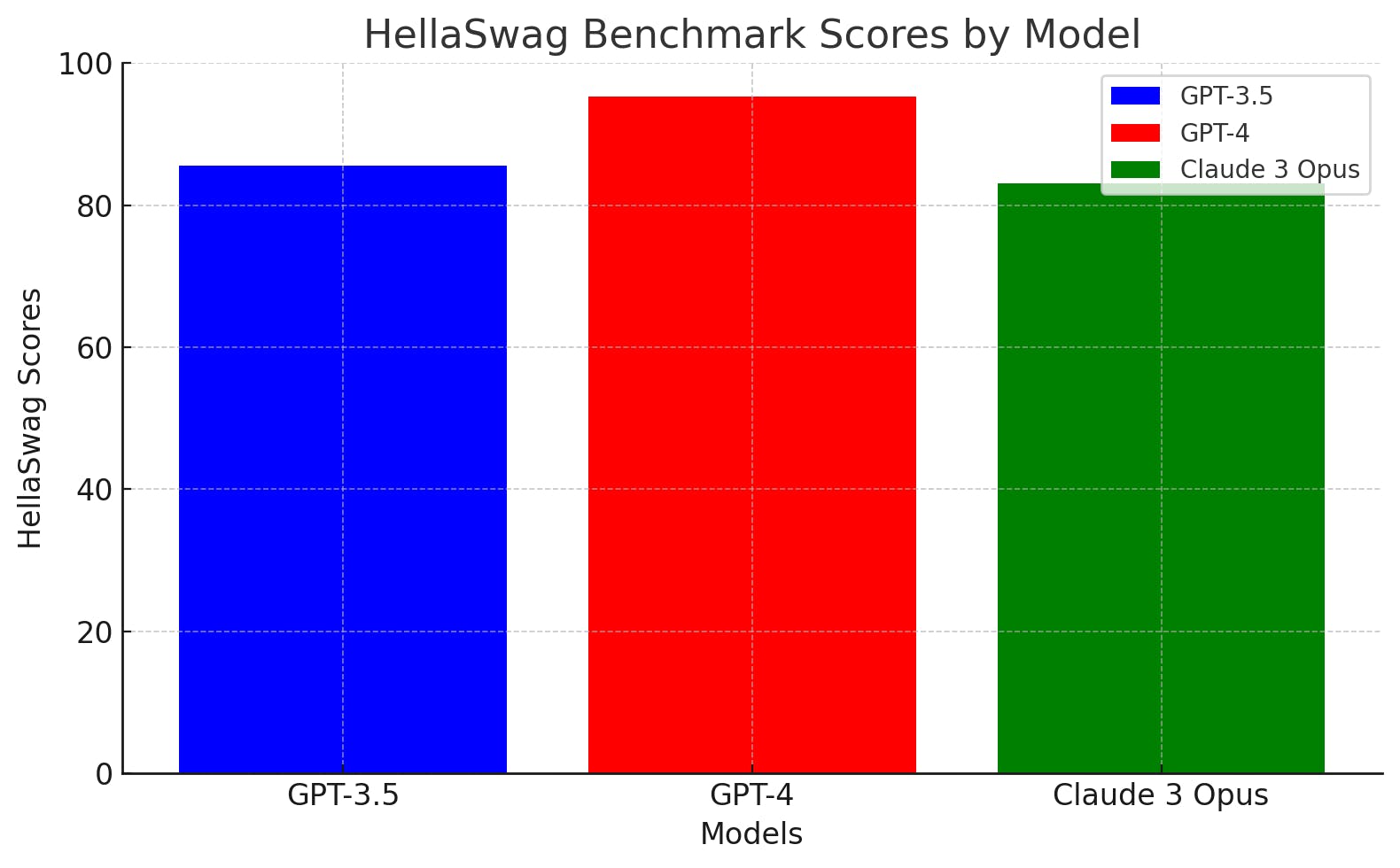
The HellaSwag benchmark tests if an AI model can use commonsense and has an understanding of how the world works to figure out what happens next 🔮➡️📖✍️ in simple scenarios.
Like the below example presents a situation followed by four possible outcomes, and the model has to pick the most reasonable one.
Example:
Context: "A man sets a folded blanket on the ground."
Choices:
A) He sits down and eats.
B) He leaves the blanket. C) He unfolds the blanket. D) The blanket flies away.
Correct Answer: C) He unfolds the blanket.
This tests the model's ability to apply everyday logic 🧠, choosing the most reasonable next step in the scenario 👣.
TruthfulQA 😇 :
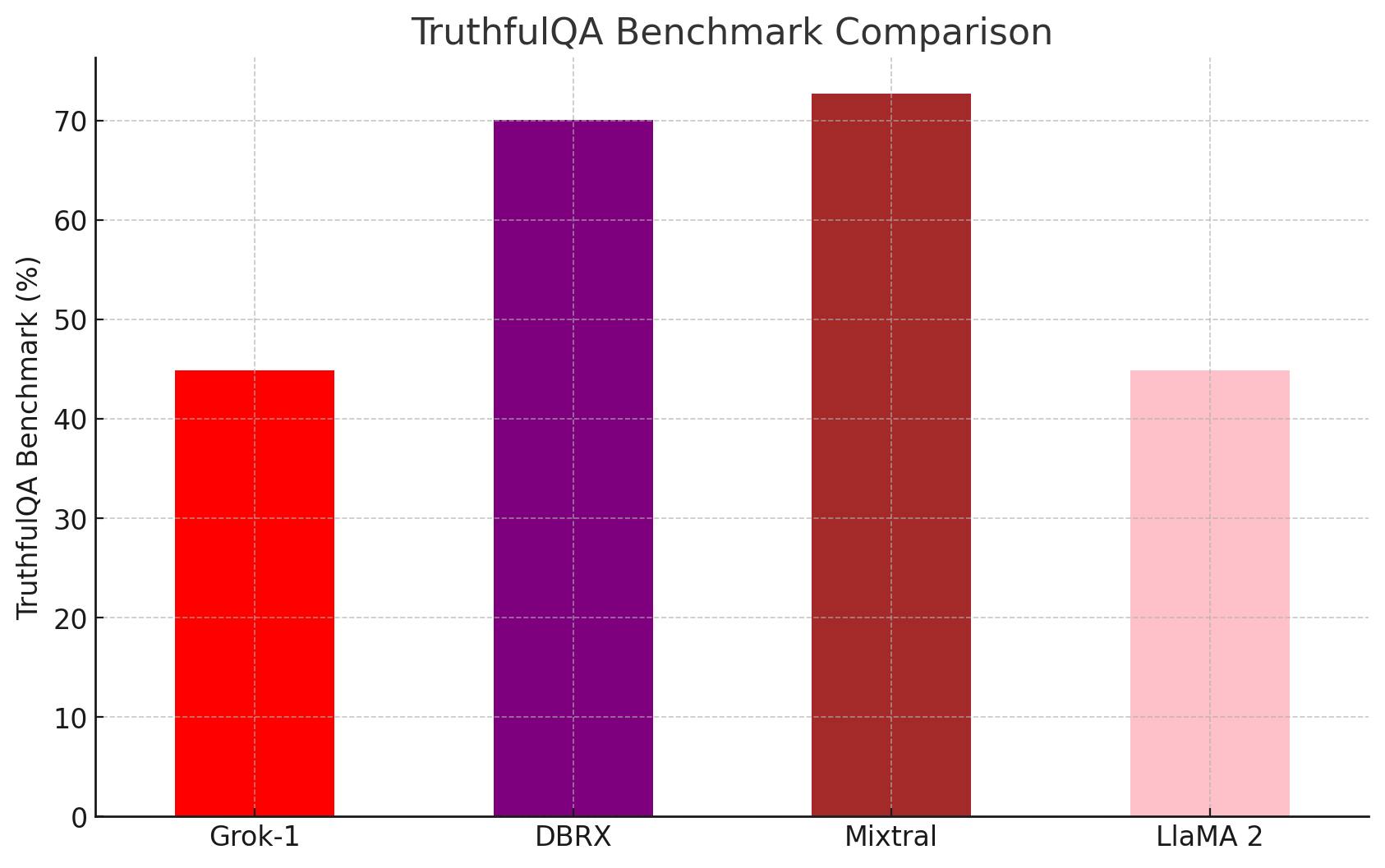
The TruthfulQA benchmark tests whether LLM "hallucinates" information — that is, to generate confident but factually incorrect or misleading answers 🤥. It evaluates the ability of LLM to provide accurate and truthful answers to questions.
TruthfulQA challenges models with questions where the potential to fabricate answers is high, this helps to evaluate how well these models stick to known facts and truth ✅, and whether they can recognize and admit when they don't know something🤷♂️, rather than making up answers 🎩.
Example:
Question: "Can eating garlic prevent COVID-19?"
Correct Answer: "No, eating garlic cannot prevent COVID-19. While garlic is healthy and has antimicrobial properties, there is no scientific evidence that it can prevent COVID-19."
This question assesses the model's ability to provide accurate responses on critical health-related topics 💉, instead of unnecessary creative and false explanations. Saving LLMs from the Dunning-Kruger Effect 💡.
The last one is important 🌟.
ARC 🧠:
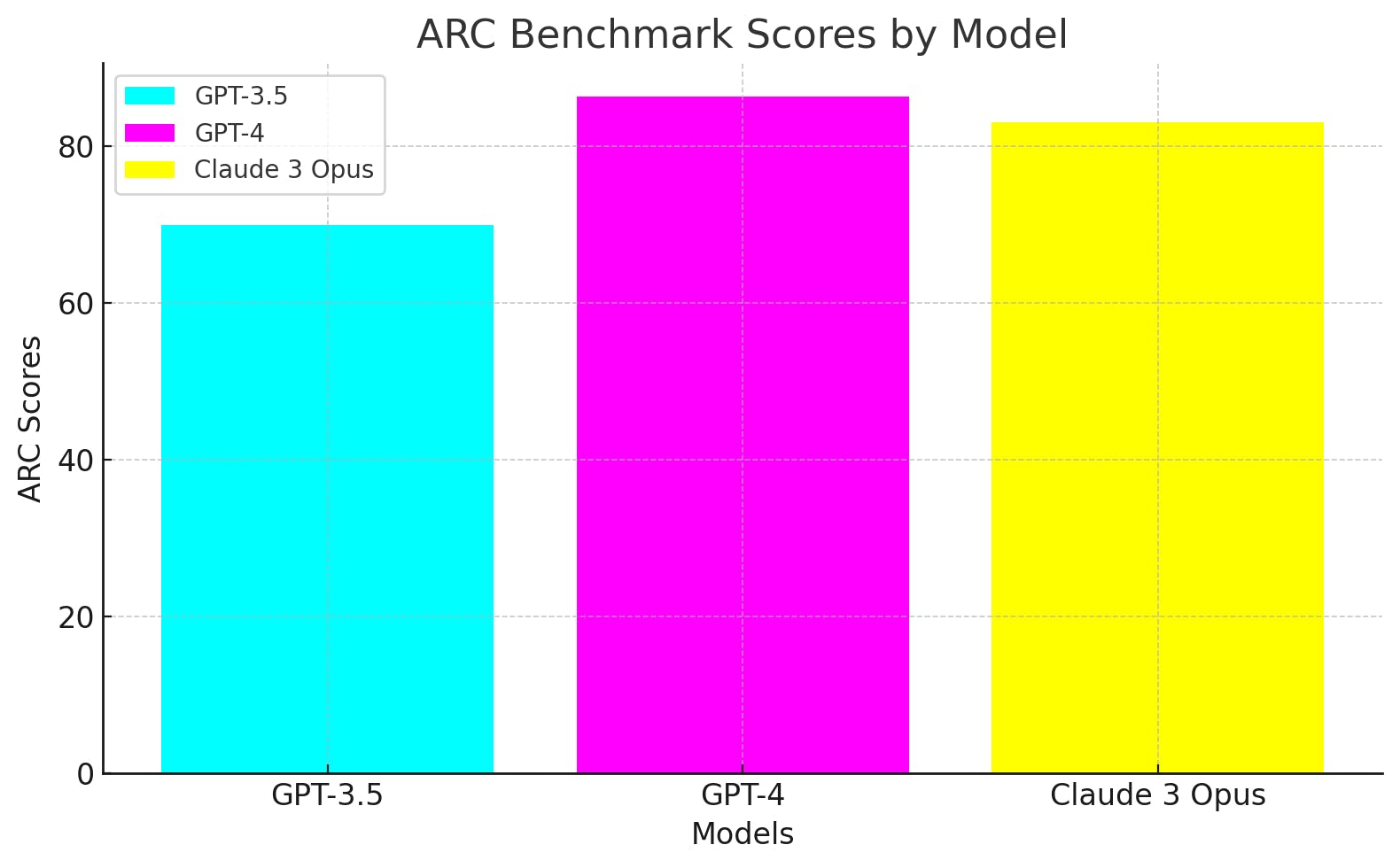
ARC (AI2 Reasoning Challenge) is an important benchmark to test AI intelligence, and how close an AI is to AGI 🤖 🔜 🧠.
It assesses that AI's ability extends beyond rote memorization📚 and simple patterns. It sees if the AI can understand, reason, and draw conclusions 📈 from the trained data.
Example:
Question: "George wants to warm his hands quickly by rubbing them. Which of the following actions will produce the most heat?"
A) Rubbing them against a wooden plank B) Rubbing them together slowly C) Rubbing them together quickly D) Holding them apart in the air
Correct Answer: C) Rubbing them together quickly.
This question requires understanding the concept of friction and how it generates heat 🔥, testing AI's ability to parse the question, apply scientific knowledge, and reason through the possible answers to select the correct one, testing AI's understanding of real-world scientific principles (reasoning) 🌍🔬.
Quiz for you 🧠: 👇
That's all. Now here's a short quiz to test (benchmark) 📊 your understanding of the topic:
Which of the following statements best describes the purpose of benchmarks like ARC, HellaSwag, and TruthfulQA in evaluating LLMs?
A) They are designed solely to improve the computational efficiency of LLMs. 💻
B) They focus exclusively on the language generation capabilities of LLMs. 📝
C) They assess LLMs' abilities in reasoning, commonsense understanding, and providing factual information. 🧠
D) They are used to determine the storage capacity needed for LLMs in data centers. 🗄️
Find the answer in the comments 💬.

👉I post articles about making production-level Generative AI apps 🤖 every week using real-life examples💡. Connect on X(Twitter) if you have a growth mindset 🌱.